如何使用JDK剖析Java应用
在JDK中,我们接触最频繁的就是java和javac。其他工具,平时接触较少,看了文章也很难记住。如果单纯介绍每个工具的用途, 比较枯燥,也脱离实际,很难留下印象。刚好之前,公司的某个服务在线上出现了一个诡异的问题,本人借助jdk中的工具最终成功定位到了根本原因(root cause)。 本文以排查这个问题的过程为例,向大家介绍JDK中一些工具的作用和使用方式,以及总结从中学习到的经验教训。
线上报警
某一天,突然收到了报警,某台服务器的cpu负载过高。我第一时间登录机器,使用top命令,发现是服务A的进程导致的,而上层调用方也反馈服务A的接口有时响应缓慢,部分请求被拒绝。当时我先使用了之前部署好的脚本(后文给出)收集现场信息,然后重启服务。重启后负载就降下来了。这里我遵循了故障处理的重要原则:遇到故障时,首先保存现场环境,然后尽最大可能恢复服务。
如果没有保存现场环境,那么后面无法找到造成问题的原因。而下一步不是开始找出问题的根源,而是采取措施恢复服务。《SRE:google运维解密》一书中也提到同样的观点(参见中文版书第十二章定位这一节,P120)。书中举了飞行员的例子:
在紧急情况中,飞行员的首要任务是保持飞机飞行,相比保证乘客与飞机安全,故障定位和排除是次要的。
另一方面,服务A是多节点部署,前面使用负载均衡。因此只需要将出问题的节点从负载均衡中移除,进行重启,而不需要担心服务会中断。这说明了高可用的架构的重要性,保证了服务的质量,也让我们更从容地处理问题。
同样的问题当日又出现了几次,而且在另外一个节点也出现了。因为原因尚未找到,也是通过重启解决。而在接下来的几天,就都恢复正常了。
诡异的问题
服务A近期没有大的改动,如果是严重的bug,应该在测试环境、预发环境或者最近一次发布到线上的时候就暴露出来了。在日志中,只发现了消息队列的超时异常,一开始认为可能是消息队列服务异常导致的,但是看了消息队列客户端代码,也和消息队列的服务提供方进行沟通,并没有找到造成CPU使用率高的原因。日志中找不到线索,问题也只在当日出现了几次,后面再也没出现,看似偶现,那么如何进一步排查呢?这就必须借助当时采用的脚本保存的现场环境的信息了。
排查问题
使用jstack分析线程
当时使用了top -H 查看了导致高CPU使用率的线程,如下图所示:
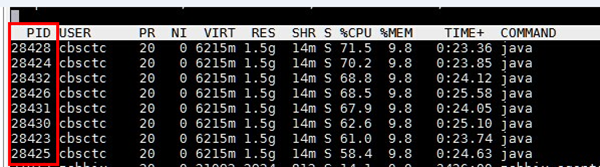
如图所示,服务A的数个线程的CPU使用率相当高。那么我们如何知道这些线程在应用中是干什么的呢?这就必须借助jstack了。在脚本中的命令如下:
1
| |
jstack将发生问题那一刻应用的线程堆栈信息保存下来了,结果如下图所示:
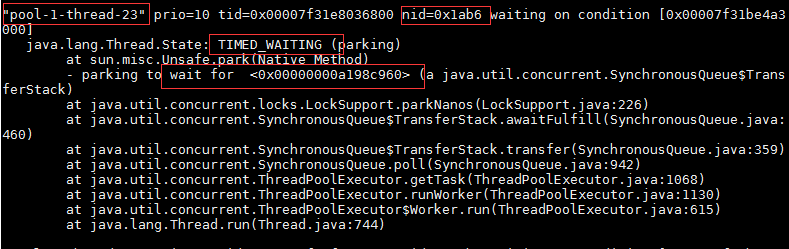
从图中可见,jstack的结果包含了线程的名字,状态,持有或者等待的锁等信息,而第一行中的nid则是线程id的十六进制。即将图1的pid转为十六进制,在文件中搜索,就可以找到造成问题的线程。如下图所示:
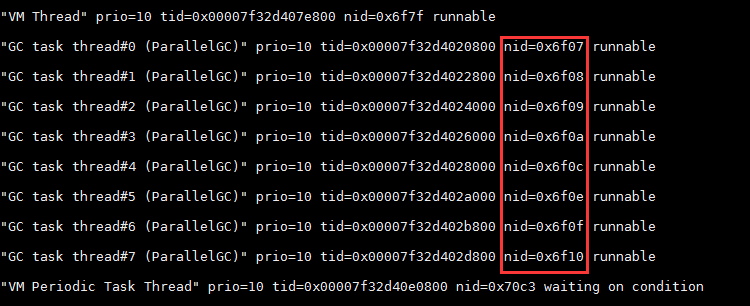
可以看到这些线程都是GC线程。假设找到的线程不是GC线程,而是图2中的线程,那么通过线程名字,我们无法知道这些线程属于哪个模块,这是一个重要的经验教训:要为所有线程池和线程合理的命名,这对定位问题十分重要。
如果没有取名,一般默认是pool-1-thread-23这样的名字。那么哪怕我们根据pid在dump文件中找到了这些线程,也不知道它们在应用中的作用。所以为线程池取名,可以帮助我们更好的定位问题。
使用jstat查看jvm指标
接下来的问题是为什么GC线程会造成CPU使用率过高。这时可以使用jstat来查看一些jvm的统计信息。脚本命令如下:
1 2 | |
jstat -gcutil的结果如下:

jstat -gccapacity的结果如下:

上面两个图中的字段这里就不一一解释了,感兴趣的童鞋可以查看官方文档。可以看到,问题发生时应用的堆内存,不管是年轻代还是老年代,都基本耗尽了。因此JVM必须进行Full GC, 然而GC无法成功回收内存,应用就处于停滞了,同时GC线程不断尝试回收内存导致CPU上升。到这里,我们找到了导致了CPU过高的直接原因了。
使用jmap与MAT分析内存
为什么堆内存会不够呢? jmap可以用来查看堆内存中的对象数目、大小统计。脚本中命令如下:
1
| |
结果如下图所示:
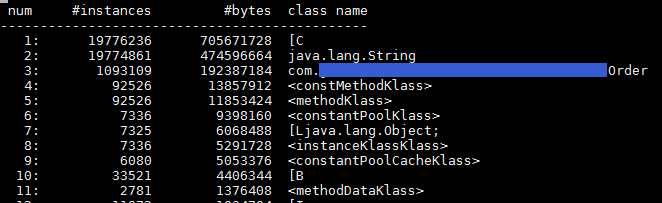
可以看到,当时应用中的Order类的实例一共有将近10万个!Order类有很多String类型的字段,因此char[]和String的实例相当多。三者占用的内存高达1.4G。对正常运行时的应用使用同样的命令,发现正常情况下内存中不会有这么多订单类实例。那为什么应用中的Order类实例突然变得如此之多呢?是因为请求量太大导致的吗?还是其他原因?这时候就可以用到剖析java应用的大杀器—jmap heap dump。脚本中的命令是:
1
| |
jmap会把当时进程内存的详细情况dump到文件,可以使用jdk中的jhat或者VisualVM来查看。这里我们使用提供更加强大功能的eclipse MAT来查看。使用MAT打开heap dump文件,首页如下图所示:
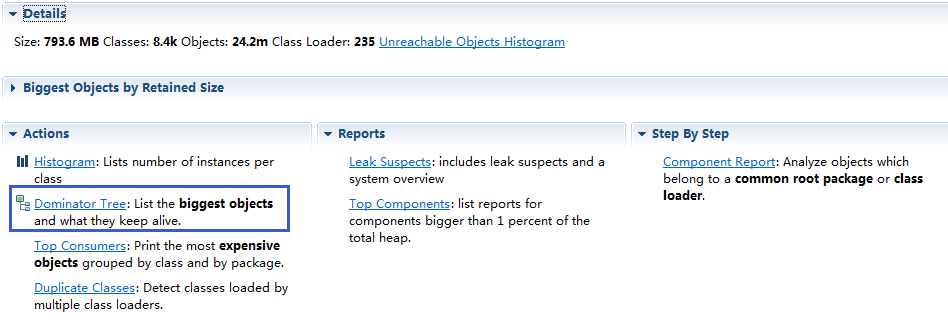
这里我们主要使用的是dominator-tree这个功能。点击后如下图所示:
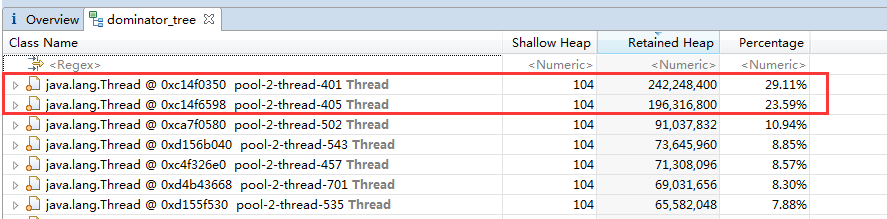
我们可以看到,排名前二的两个线程占用了超过50%的内存。我们点击展开,可以进一步查看线程内所引用的对象,如图所示:
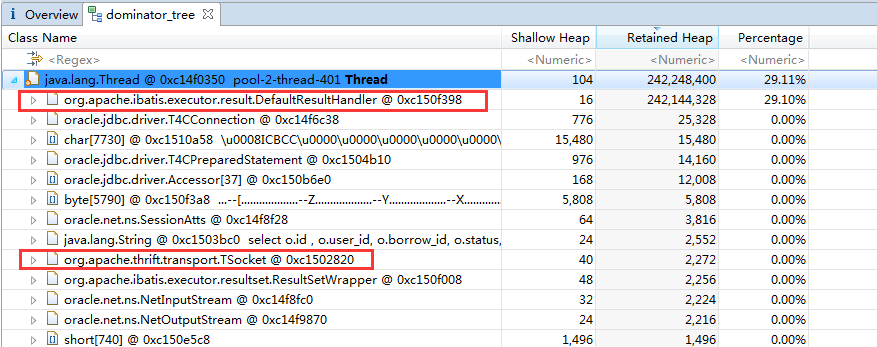
线程内有org.apache.thrift.transport.TSocket对象,因此这是一个thrift服务的线程。而MyBatis相关的类说明线程对数据库进行了操作。其中org.apache.ibatis.executor.result.DefaultResultHandler对象基本占用了线程所有的内存,点击这个对象,如图所示:
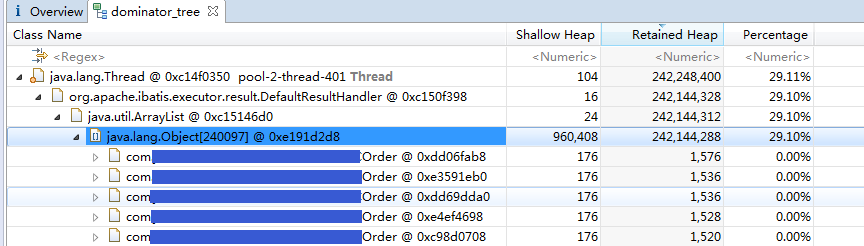
可以看到,myBatis的查询结果里面,有多个Order对象。从这里我们可以知道是某个订单查询的thrift接口导致了问题。离真相只有一步之遥了,我们进一步查看线程中相关的类:
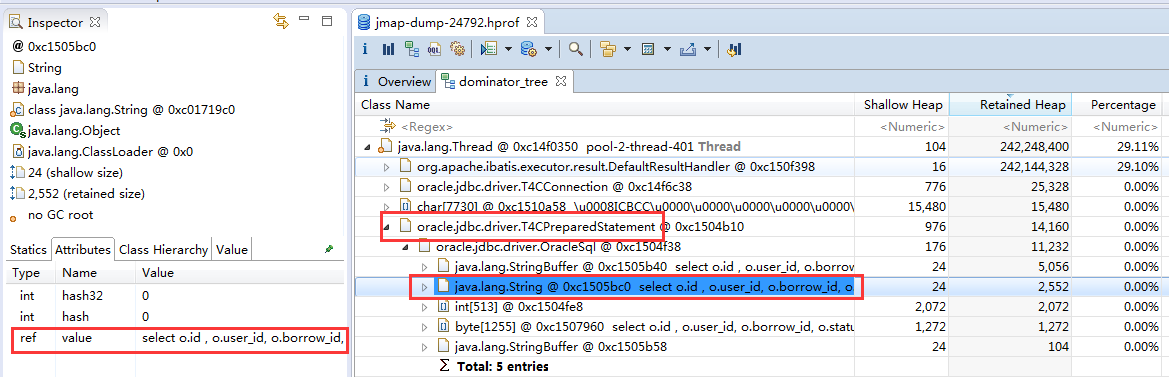
如上图所示,展开oracle.jdbc.driver.T4CPreparedStatement,对象中的oracle.jdbc.driver.OracleSql里的String的值就是这个接口查询数据库使用的SQL。
一看不由大吃一惊,查询的条件是把订单表的数据都查出来!怎么会这样呢?原来此订单接口的参数是一个结构体QueryParam,里面包含各种字段如orderId,uid,startData,endDate等。上层调用者可以根据设置不同的字段以获得不同结果。比如设置了orderId则是查询某个订单,设置了uid则是查询某个用户的订单。服务会根据QueryParam的字段,使用MyBatis拼装SQL的条件。但是服务犯了一个低级的错误,即没有校验参数组合有效性,当uid和orderId同时没有设置时,构造的查询语句就会查出全表数据! 恰恰上层的应用,在线上也出现了bug,在某个极端的情况下,调用接口时uid和orderId都没有设值。
至此,问题的根源已经水落石出了。解决这个问题十分简单,只需要加上参数校验,当uid和orderId都为空时直接返回错误就可以了。这个例子很好的说明了,越诡异越隐蔽的问题,往往是多个简单的错误联合起来造成的。这在安全领域更加明显,很多高危的漏洞,都是利用多个环节上存在的低级漏洞。因此提高代码质量,遵循规范,尽量杜绝低级的错误,对软件的健壮性和安全性有重要意义。
回顾与总结
简单回顾一下整个排查问题的过程:
1. 使用top -H找出造成问题的线程的pid。
2. 使用jstack的找出问题线程属于应用的GC线程。
3. 使用jstat查看应用JVM的GC指标。
4. 使用jmap和MAT分析内存,找出根本原因。
我们从中学习到的经验教训:
1. 遇到故障时,首先保存现场环境,然后尽最大可能恢复服务。
2. 服务应该采用高可用的架构。
3. 所有线程池和线程都要有合理的命名,这对定位问题十分重要。
4. 服务器必须校验请求参数的有效性。
5. 提高代码质量,遵循规范,尽量杜绝低级的错误,对软件的健壮性安全性有重要意义。
通过这个案例,我们可以看到jdk的工具十分强大,能够帮助开发人员深入剖析运行中的应用,在定位问题发挥重要作用。每个Java程序员都应该掌握和理解这些工具。